
X Ogólnopolska Konferencja Bibliotek Szkół Wyższych Niepaństwowych
Mgr Urszula Ganakowska – sekretarz naukowy
Mgr inż. Wojciech Zatorski – informatyk
Biblioteka Główna Uniwersytetu Szczecińskiego
KOHA – alternatywa dla komercyjnych systemów bibliotecznych (fragment)
Abstrakt
Zintegrowany system biblioteczny KOHA używany w bibliotekach szkolnych, publicznych i innych o charakterze non-profit w wielu krajach na świecie doczekał się również pierwszego pełnego wdrożenia w Polsce. Biblioteka Główna Uniwersytetu Szczecińskiego jest w trakcie jego implementacji do swojej działalności. Pierwszym krokiem w tym kierunku była instalacja stanowisk komputerowych z zainstalowanym systemem Linux. Etap kolejny stanowiło i nadal stanowi wdrażanie zintegrowanego systemu bibliotecznego Koha opartego na zasadach open source. Równolegle wprowadzana jest integracja innych usług powiązanych systemem bibliotecznym (identyfikatory, elektroniczne zarządzanie obiegiem dokumentów, centralny fax, centralne bazy sprzętu i użytkowników).
Biblioteka Główna Uniwersytetu Szczecińskiego (BG US) już trzeci rok z powodzeniem wdraża zintegrowany system biblioteczny Koha dostosowując go do wymagań biblioteki uniwersyteckiej, a także polskich realiów. We wcześniejszych latach BG US pracowała w autorskim programie bibliotecznym Biblo Info, który niestety nie był już w stanie sprostać nowym zadaniom jak np. pracy wielostanowiskowej, wsparcia dla formatu MARC21 i wielu innych. W roku 2005 zaczęliśmy wdrażać system biblioteczny Aleph. Sytuacja finansowa Uniwersytetu nie pozwoliła jednak na kontynuowanie tego przedsięwzięcia, w którym pracować miały wszystkie biblioteki Szczecina, a dziś w systemie tym pracuje tylko Książnica Pomorska, Politechnika Szczecińska i Pomorska Akademia Medyczna. Po wnikliwych obserwacjach i konsultacjach wybór padł na system Koha.
Jest on w pełni profesjonalnym zintegrowanym systemem bibliotecznym udostępnianym na zasadach Open Source. OS to oprogramowanie, którego licencja pozwala na legalne i nieodpłatne kopiowane, zarówno kodu wynikowego, jak i źródłowego oraz na dowolne modyfikacje tego ostatniego. Rewolucja Open Source rozprzestrzeniła się prędko i zdominowała swoją obecnością Internet, administrację publiczną, zakłady pracy, niektóre wielkie korporacje i w ten sposób spotkała się w końcu ze światem bibliotek odkrywając je dla siebie jako środowisko naturalne.
(...)
Biblioteka US jest pierwszą i jedyną do tej pory biblioteką akademicką w Polsce, która pracuje w systemie Koha. Obecnie używana wersja znacząco różni się od oryginału, a to dzięki otwartości kodu źródłowego i co z tym idzie możliwości dowolnej modyfikacji wybranych części programu. Zmiany jakie zostały wprowadzone wynikły ze specyfiki polskiej biblioteki akademickiej. Pierwszą poważną modyfikacją było przetłumaczenie systemu (ekran po ekranie) na język używany w polskich bibliotekach. Dzięki temu praca z systemem przez bibliotekarzy stała się w ogóle możliwa (nie wszyscy znają język angielski).
Kolejny ważny krok, a może i najważniejszy to dokonanie konwersji z systemów wcześniej używanych, takich jak ISIS, MAK, Biblio Info, Aleph. Proces konwersji trwał i trwa równolegle z innymi pracami. Obecnie udało się przekonwertować większość baz używanych w bibliotece (m.in. baza Centrum Informacji i Dokumentacji Europejskiej, Katalog Biblioteki Wydziału Teologicznego), aktualnie kończona jest konwersja baz Biblioteki Narodowej (program udostępniany przez BN jest już archaizmem) oraz ostatni fragment Katalogu Głównego. Za sprawą tej pracy uzyskaliśmy ujednolicenie baz w jednym systemie, czytelnik czy bibliotekarz nie musi znać X-systemów bibliotecznych, wystarczy, że zna obsługę jednego. Ograniczyło to też koszty obsługi baz (jeden sposób archiwizacji, kontroli spójności danych, etc).
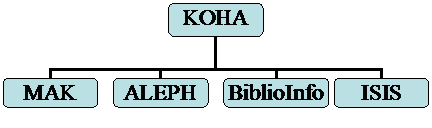
Rysunek 1 - Wszystkie bazy w jednym systemie
W związku z kolejnymi konwersjami uruchamiane są sukcesywnie kolejne instancje KOHA. Wszystkie czynności jakie należy wykonać w takim przypadku (które zajmują maksymalnie jeden dzień) to stworzyć odrębną bazę w bazie danych MySQL , osobne ustawienia oraz wygląd OPAC i INTRANET . Kod systemu jest wspólny dla wszystkich baz. Dzięki takiemu rozwiązaniu jedyną barierą jaka istnieje to ograniczenie sprzętu. Biblioteka nie musi się obawiać przekroczenia dostępnych licencji, bo takie w obecnie stosowanym podejściu nie istnieją.
Aby sprostać wymaganiom co raz to nowych baz, kolejnych włączanych oddziałów biblioteka zakupiła odpowiednią ilość serwerów. Na początku był to jeden komputer klasy Pentium 4 z 512MB RAM pamięci, a obecnie są to dwie maszyny, jedna pełniąca role głównego serwera baz danych (KOHA) z dyskami SCSI i macierzą RAID 10, a drugi (MAIN) pełniący role „niewolnika” (slave) baz danych oraz obsługującego kod aplikacji posiadający dwa procesory Xeon 5310 i 8GB pamięci RAM. Oprócz tego zakupiono serwer obsługujący pracowników pracujących na stacjach terminalowych (TS) oraz obsługującego ruch wychodzący i przychodzący (BG). Zastosowanie stacji terminalowych znacznie upraszcza sposób zarządzania siecią oraz znacząco zmniejsza koszty. Zakup terminala to obecnie wydatek około 500zł netto. W przypadku awarii takiego stanowiska, podmiana komputera na nowy z uzyskaniem pełnej funkcjonalności stanowiska zajmuje tylko okres wymiany sprzętu.
Wszystkie serwery podłączone są do wydajnego zasilacza awaryjnego UPS o mocy znamionowej 2200V, co pozwala na nieprzerwaną prace przez 40 minut od utraty zasilania. Prócz inwestycji w serwery dokonano również rozbudowy mocy przesyłowej sieci szkieletowej biblioteki. Stara sieć o przepływności do 100Mbit/s nie wytrzymywała generowanego obciążenia przez nowe rozwiązania (typu praca terminalowa). Obecnie przepływność między serwerami i komputerami wynosi 1Gbit/s. Dzięki temu czas archiwizacji i wymiany danych pomiędzy serwerami spadł do kilkunastu minut, a czas oczekiwania na odpowiedz serwera na zapytanie przez klienta zmniejszyło się kilkukrotnie. Również wszystkie urządzenia sieciowe podłączone są do zasilania awaryjnego pozwalające na nieprzerwaną prace oddziałów przez 40 minut od utraty zasilania. Jedynym obecnie problemem jest wydajność sieci uczelnianej, która na niektórych odcinkach nie przekracza 100Mbit/s. Na przyszłe lata planowane są kolejne inwestycje w sieć zwiększające wydajność do 10Gbit/s, co pozwoli integrować kolejne usługi.
Rys. 2. Poglądowa struktura sieci BG
Źródło: opracowanie własne
Wydajność systemu nie była poprawiana tylko przez zmianę i dokładanie kolejnego sprzętu. W systemie dokonano kilku podstawowych zmian powodując zwiększenie ogólnej wydajność ponad dziesięciokrotne. Między innymi poprzez zastosowanie modułu mod_perl , modułu eAccelerator , rozłożenie ruchu na dwie maszyny, ograniczenie generowanego ruchu poprzez np. kompresje przesyłanego rezultatu do klienta. Wszystkie te prace wymagały dosyć poważnych ingerencji w kod aplikacji, sam mod_perl wymagał zmiany we wszystkich modułach systemu, a rozłożenie ruchu zmian koncepcyjnych.
Biblioteka nie tylko skupiała się na poprawie wydajności systemu, ale również na brakujących funkcjach. Rozbudowano ilość możliwych połączeń w tabelach pomiędzy bazą KOHA a bazą MARC (np. o sygnatury), dodano licznik inwentarzy (kolejne numery nadawane są przez system i pilnowane, aby się nie powtórzyły), zaimplementowano pełne wsparcie dla kodów kreskowych EAN13, dzięki temu znacznie uproszczono prace z systemem. Obecnie wypożyczalnie w większości zadań posługują się jedynie czytnikiem oraz myszką, a wyszukanie czytelnika czy książki wymaga jedynie sczytania kodu kreskowego na jakimkolwiek ekranie systemu.
Rozbudowany został również moduł raportowania, dodano między innymi pełne statystki na temat pracy pracowników zawierające, ile, kto i kiedy dokonał zmian w egzemplarzach, opisach, czy czytelnikach, historie egzemplarza (kto, kiedy i na jaki czas), ostatnie zapisy w oddziałach, pokazujące informacje o nowych czytelnikach, czy choćby księga inwentarzowa zgodna z polskimi normami.
Poszerzono uprawnienia dodając poziomy uprawnień (ktoś kto ma poziom 4 nie może poprawiać rekordów kogoś, kto ma np. poziom 5), możliwość określenia do jakich egzemplarzy ma dostęp dany pracownik oddziału, określające ile czasu pracownik ma na prace w systemie bez odświeżenia ekranu, itp.
Rys. 4. Fragment ekranu uprawnień
Źródło: opracowanie własne
Dzięki dostępności kodu źródłowego wszelkie błędy w oprogramowaniu mogą być naprawiane „od ręki”, przed wyrządzeniem poważniejszych szkód w zawartości bazy. A zmiana położenia choćby najmniejszego przycisku nie wymaga konsultacji z producentem.
W ramach interoperacyjności system KOHA łączony jest z systemem uniwersyteckim prodziekan, przez co import danych osobowych studentów będzie wymagał podania przez przyszłego czytelnika swojego numeru PESEL.
Obecnie rejestracja dokonywana jest przez formularz, każdy rejestrujący otrzymuje swój unikalny numer. Z tym numerem udaje się do wypożyczalni, gdzie po weryfikacji danych następuje import do systemu i aktywacja konta.
W ramach integracji połączono system kadrowy z KOHA, dzięki temu identyfikator pracowniczy jest również kartą biblioteczną. A czytelnikowi w przyszłości wystarczy dowód biometryczny zamiast karty bibliotecznej czy legitymacji do korzystania z usług bibliotecznych.
Planowane jest włączenie zdalnego dostępu do baz obcych przez wykorzystanie loginu oraz hasła z systemu bibliotecznego. Wskutek tego każdy czytelnik będzie mógł z domu korzystać z baz zakupionych przez BG.
System KOHA nie składa się wyłącznie z samej aplikacji bibliotecznej, w skład całego środowiska wchodzą (jak już wspomniano) stanowiska terminalowe (pod kontrolą systemu Linux), komputery kioski (również Linux’owe), a w przyszłości również zintegrowany system archiwizacji dokumentów (faktury, rachunki, pisma, etc.).
Te wszystkie zmiany nie byłyby możliwe bez Open Source…
MySQL jest jedną z najpopularniejsza na świecie baz danych. Dzięki swojej wydajności, szybkości działania, stabilności i rozbudowanym mechanizmom zabezpieczeń jest wykorzystywana niemal do wszystkich zadań, do jakich może być potrzebna baza danych. Bogactwo funkcji i możliwości to ogromna zaleta środowiska MySQL.
Moduł mod_perl jest unikalnym oprogramowaniem integrującym użyteczność Perla z elastycznością i stabilnością serwera WWW. Zastosowanie modułu podniosło wydajność skryptów perl w najgorszym wypadku 15 krotnie
eAccelerator powstał na bazie Turck MMcache, oferuje dynamiczne zarządzanie pamięcią podręczną skompilowanych kodów bajtowych oraz zakodowanych skryptów php. Po zainstalowaniu eAccelerator optymalizuje skompilowany kod bajowy i zapisuje go do pamięci oraz dodatkowo do pamięci współdzielonej lub na dysk.